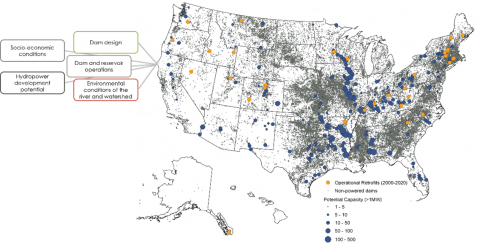
Dataset Overview
The U.S. Non-Powered Dam (NPD) Characteristics Inventory contains data from various sources, including identifiers, locations, and a wide variety of characteristics. These characteristics included describe US NPDs and their surroundings, including attributes related to the physical nature or design of a dam, environmental conditions, safety conditions, socioeconomic aspects, and hydropower development potential. Data may be continuous or discrete/categorical. Data were obtained for each dam listed as an NPD (based on USACE NID). This inventory supports the NPD Explorer and NPDamCAT web apps developed by ORNL. This dataset was developed under the Standard Modular Hydropower Technology Acceleration project, funded by the U.S. Department of Energy’s Water Power Technologies Office. The data is intended to aid in aggregating and disseminating data on characteristics of non-powered dams in the U.S.
Data are sourced using the following methods:
- Data may be collected from existing sources that are readily referencing either a dam or its associated hydrography feature using unique dam ID or hydrography ID (e.g., NHD Common Identifier [COMID] or hydrologic unit code).
- Data may be extracted from spatial data sets using standard geographic information system (GIS) processing (e.g., spatial intersect or spatial joins).
- Data may be calculated from model outputs.
Attributes for the various characteristic themes (operational, design [age, materials and architectural/structural, size/dimensions, water conveyance], hydropower opportunity, socioeconomic, and environmental [hydrology, climate, landscape, water quality, geology]) were obtained from a variety of sources. Each attribute is documented in the metadata file, including:
-
associated field name (limited to 10 characters to comply with the standard ESRI shapefile format),
-
a brief description,
-
units,
-
suggested classes (may be the available values of categorical data or suggested thresholds for continuous data that are based on existing design, safety, or other guidelines),
-
User-defined indicates that no suggested class exists; classes may be defined entirely based on the user’s objectives and preferences.
-
Not applicable indicates that classes may not be appropriate to assign. The characteristic may be more appropriately viewed as an identifier (such as the ID of the NHDPlus stream reach) or for filtering (such as the state or county in which the dam is located).
-
source of the data, and
-
type of data (text or numeric).
A series of basic quality checks was performed to improve use and understanding of the data. Because the U.S. Corps of Engineers’ NID (a major source of information for the dataset) is a collection of data from many state and federal agencies, problems with different reporting methods and accuracy cause issues with a small segment of the dam population. Several issues and the checks were performed to remedy or identify the potential issue as described below:
-
Filtered out auxiliary structures.
-
Filtered out dams that are listed multiple times.
-
Removed dams with incomplete location information.
-
Corrected locations.
-
Filtered out dams that have been removed.
-
Added an indicator for dams that may have hydropower or support hydropower, but they are not indicated as a powered dam in the NID.
Several data-cleaning and standardization processes were applied to present the data in a form that is more convenient for classification and querying.
-
Missing data. For example, in the NID, some fields are blank, and others contain 0 to signify that there is no value or that the value is missing. However, not all 0 values reflect missing data (e.g., the number of locks may be 0, so they may not be treated the same way as afield in which the number of locks is simply unreported). In this NPD characteristics inventory, missing data are instead coded with a -99999 value.
-
Aggregation. If categorical data have many values or if they lack vocabulary constraints, then values may be aggregated to facilitate better filtering or grouping. For example, the NID reports dam owner name, but it also allows many unique names for the same agency. One dam may be reported as owned by the United States Bureau of Reclamation, while another is reported as owned by the U.S.B.R., and another is owned by the US Bureau of Reclamation. Rather than force all users to implement a data cleaning/standardization process, values have been aggregated and are made available through the NPD Explorer and NPDamCAT in ways that are conducive to quick subset creation or analysis (i.e., the user should only be required to select one value to see dams owned by the USBR).
-
It is important to note that due to the large size of the dataset, manual verification of all locations is not feasible. There may be inaccuracies that propagate in cases where individual dams with incorrect or inaccurate locations are joined to a flowline or watershed boundary that is used to join to other data. For example, the StreamCat dataset references NHDPlusV2 flowlines; any StreamCat characteristics for a dam assume that the flowline the dam is joined to is accurate.